
Why bpmn-to-code
You have just modeled a process. Tasks, messages, signals, timers — laid out in Camunda Modeler. Now you need to implement it. You open your IDE and start wiring the code to the process model.
This is what that looks like:
// Scattered across your codebase
client.newWorker()
.jobType("Activity_ConfirmRegistration") // copy-pasted from the modeler
.handler { ... }
.open()
correlationClient.newPublishMessageCommand()
.messageName("Message_SubscriptionConfirmed") // hope nobody renames this
.correlationKey(subscriptionId)
.send()You copy these strings from the modeler. If someone renames a task or refactors a message name, nothing breaks at compile time. You find out at runtime — when a worker stops picking up jobs or a message correlation silently fails.
What bpmn-to-code Does
bpmn-to-code reads your BPMN files and generates a typed Process API from them. Every element ID, message name, and signal reference becomes a constant — derived directly from the XML, on every build.
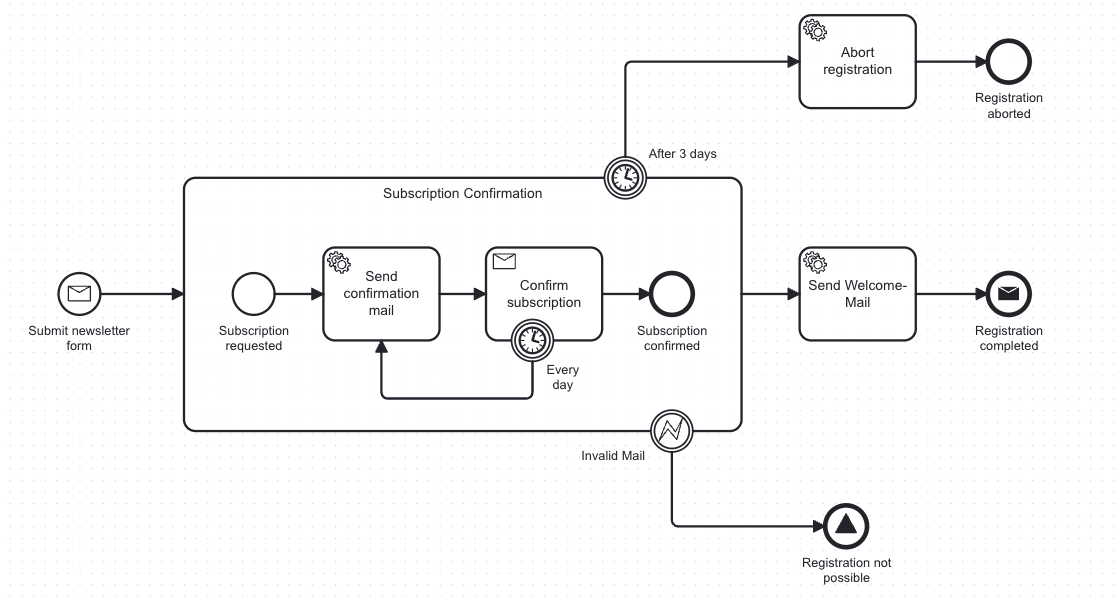
For a newsletter subscription process like the one above, bpmn-to-code generates something like this:
// Generated by bpmn-to-code from the BPMN model
object NewsletterSubscriptionProcessApi {
const val PROCESS_ID = "newsletterSubscription"
object Elements {
const val ACTIVITY_CONFIRM_REGISTRATION = "Activity_ConfirmRegistration"
const val ACTIVITY_SEND_WELCOME_MAIL = "Activity_SendWelcomeMail"
}
object Messages {
const val MESSAGE_SUBSCRIPTION_CONFIRMED = "Message_SubscriptionConfirmed"
}
}The hardcoded strings from before are now typed constants:
// Using the generated Process API
client.newWorker()
.jobType(NewsletterSubscriptionProcessApi.Elements.ACTIVITY_CONFIRM_REGISTRATION)
.handler { ... }
.open()
correlationClient.newPublishMessageCommand()
.messageName(NewsletterSubscriptionProcessApi.Messages.MESSAGE_SUBSCRIPTION_CONFIRMED)
.correlationKey(subscriptionId)
.send()Typos become compiler errors. Renamed elements break the build before they break production. Your IDE knows every process element by name. The model and the code stay in sync — automatically.
Does AI Make This Obsolete?
My name is Marco. I built bpmn-to-code to solve exactly this. If you're interested in the whole story, you can find it here. Lately, I have been asking myself whether it was the right call — or whether AI has already made it obsolete.
AI coding assistants are getting better every month. They read XML, understand process structures, and generate code. You can paste a BPMN file into Claude, describe what you want, and get typed constants back.
You could even build an AI Skill that replaces the plugin entirely — scan the project for BPMN files, generate all the constants, write the output to disk. No build plugin, no configuration, no dependency.
And honestly? I can't fully deny that. So I figured I'd make it official. I pointed bpmn-to-code at Death by Clawd — a tool that (even if not dead-serious 😄) scores how easily AI can replace a software product:

And the verdict was clear: 91 out of 100. Already dead. Cause of death — Prompt engineering presented as a product.
My defense? None. Guilty as charged — unless you ever need to do this more than once.
Why It Still Makes Sense
Every time your BPMN model changes, you rebuild — and the Process API updates automatically. Your IDE knows every element by name. Rename a task in the modeler, and the compiler tells you exactly what broke. No string search, no grepping through the codebase, no silent failures at runtime.
And when generation is wired into your build, it runs the same way everywhere — on every machine, every branch, every CI pipeline. That shifts the question from "can AI produce this output?" to "can I trust this output unconditionally, on every run, with no external calls?"
This is where bpmn-to-code shines:
- Deterministic output — Same BPMN in, same code out. Every run, every machine, every time. An LLM can vary across model versions, reorder fields, or introduce formatting drift. Diffs stay clean only when output is byte-identical.
- No hallucination risk — The plugin maps XML to code via deterministic rules. It cannot invent an element ID or silently drop a service task. Build pipelines need guarantees, not probabilities.
- No external dependencies — No network calls, no API keys, no rate limits, no model deprecations. Works offline. Never flakes because a provider had an outage.
| Concern | Build plugin | AI Skill / LLM |
|---|---|---|
| Output stability | Byte-identical | May vary across model versions |
| CI/CD | Offline, no API dependency | Requires network + API key |
| Hallucination risk | None | Possible invented IDs or drift |
What I Suggest
Use the plugin for deterministic generation. Use AI for everything around it:
- Setting up the plugin in a new project — detecting BPMN files, configuring the build, choosing the right engine.
- Migrating existing codebases from hardcoded strings to the generated type-safe API.
- Scaffolding worker implementations, REST controllers, and test boilerplate from the generated Process API.
Thus, bpmn-to-code ships with AI Skills that automate these workflows and an MCP Server for AI-assisted generation inside your editor. Both are optional — the build plugins work standalone.
How to Get Started
The generation engine is the same everywhere. Pick the format that fits your workflow.
| Format | Best for | |
|---|---|---|
| Gradle plugin | JVM projects using Gradle | Setup guide |
| Maven plugin | JVM projects using Maven | Setup guide |
| Web app | Trying it out, one-off generation, non-JVM projects | Web app |
| MCP server | AI-assisted generation inside your editor | MCP Server |